

The Search That Fools You
When a Data Engineer role lands on your desk, most recruiters open their ATS or LinkedIn and type exactly two words: Data Engineer.
Nothing wrong with that. It's logical. It's fast. And it puts you in a queue with roughly every other recruiter working the same role.
Same keywords. Same boolean strings. Same candidate pool. The only thing separating you from the competition at that point is how fast you move, and that's a race nobody wins cleanly.
But there's a bigger problem hiding inside that simple search. It misses candidates who deserve to be found. And it surfaces candidates who don't.
The Profile That Slips Through
Think about this candidate for a moment.
Five years building ETL pipelines. Proficient in Python, SQL, and Spark. Has worked with Airflow, designed data models, and knows what a slowly changing dimension is. On paper, they have everything you'd check for in a Data Engineer.
Except their title says ETL Developer. Or Data Integration Engineer. Or sometimes just Developer.
They're not hiding. They're just describing themselves the way their job was labelled, not the way your JD is written.
A keyword search for "Data Engineer" walks right past them. Meanwhile, another recruiter who thinks in terms of what the person actually does finds them. And places them.
This is the gap. Not a skills gap. A language gap.
The Profile That Overreaches
There's another candidate who shows up in every "Data Engineer" search.
Their headline says Data Engineer. Their summary uses all the right words: pipelines, Spark, data architecture. They've even listed dbt and Kafka in their skills section.
But when you dig into the experience, something feels off. Responsibilities described at 30,000 feet. No specifics about what they built. No trace of the problems they solved.
They've learned the vocabulary. They haven't done the work.
This is the other failure mode of keyword search. It doesn't just miss the right candidates, it actively surfaces the wrong ones. And in a market where "Data Engineer" has become a career aspiration badge, the signal-to-noise ratio on that keyword has quietly gotten worse.
How Candidates Describe Themselves vs. How JDs Are Written
This is the core problem in technical recruiting, and it doesn't get talked about enough.
Job descriptions are written in aspiration language. Candidates write their profiles in experience language.
A JD says: "Experience with data pipeline orchestration tools." A candidate writes: "Built and maintained Airflow DAGs for daily batch processing."
Same thing. Completely different words.
If your search only speaks JD language, you're systematically missing candidates who are writing in experience language. And the better the candidate, usually the more they write about what they actually did, not what category it falls into.
What SignalScoper Does Differently
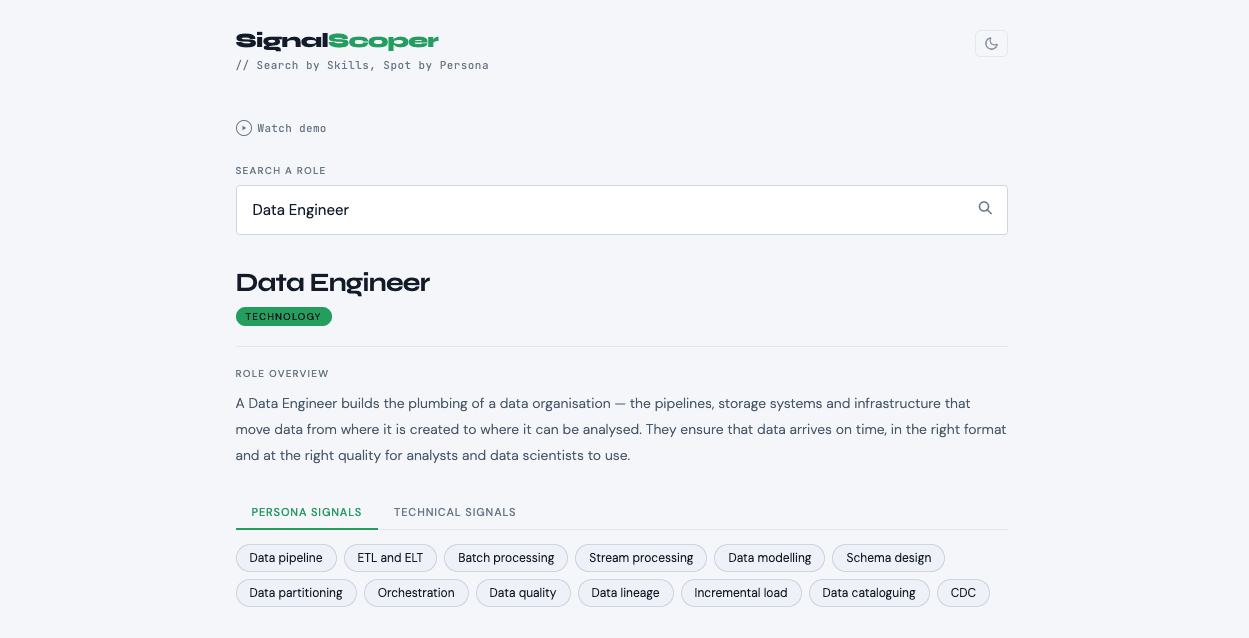
SignalScoper was built around one idea: search for the person, not the title.
Every role profile is built around what that type of professional actually writes on their profile. Not what a JD says. Not what a recruiter hopes to see. What the candidate uses to describe their own work.
For a Data Engineer, that means surfacing signals like pipeline architecture, batch vs streaming, orchestration, schema evolution, data contracts, ELT vs ETL, incremental loads. Terms serious practitioners reach for naturally because they've lived them — not because they saw them on a job description.

But it also captures the adjacent signals. The ETL developer writing about migrating batch pipelines to Spark. Working with dbt. Thinking about data modeling. These are aspiration signals. Not there yet by title, but clearly moving in that direction. Some hiring managers want exactly that profile: strong fundamentals, actively levelling up.
SignalScoper lets you find both. The established Data Engineer and the one who's three-quarters of the way there.
What Depth Signals Reveal
A candidate who has genuinely worked in data engineering doesn't just mention Airflow. They talk about DAG design, backfill strategies, task dependencies. They don't just list Spark, they write about partitioning, shuffle optimization, cluster tuning. They've had opinions about schema evolution because they've been burned by it.
That level of specificity doesn't appear in a profile that's been dressed up with keywords. It shows up when someone has actually been in the weeds.
When you search using SignalScoper's signals, you're not just matching on tool names. You're filtering for the vocabulary that comes from experience. The overreaching candidate might clear a keyword filter. They're far less likely to clear a signal filter.
Sourcing at the Persona Level
The most interesting use case isn't finding the obvious Data Engineer. It's finding the person who will be an obvious Data Engineer in six months — and screening out the person who's been one only on paper.
That requires thinking in personas, not titles.
SignalScoper also generates the boolean string for you, built from a researched, tested library of terms that reflects how practitioners actually describe their work. You can edit it, and you should. But the starting point is significantly better than what most people build from scratch under deadline pressure.

The result: more reach on the candidates worth finding. Less noise from the ones who aren't.
SignalScoper is free. No account. No signup. Try it at signal.sourcer.club
Happy Recruiting!



